I sent CRISPR knockout screens to space. They didn't grow.
I'm a bioinformatics postdoc. I sent CRISPR knockout screens to space — first of their kind. The cells didn't grow enough to give us hits. That's most of science.
I know graduate students who never graduated, postdocs who never moved on, because their results said no. This tool is for them.
When biology becomes a search problem — and AI is making it one — the cost is paid in failed trials. The map of where not to go is the map worth building.
Writes 5 kill tests — before any data, before any law
Opus 4.7 · Proposer
Proposer
Law families — written after kill tests are locked
PySR
Searcher
Symbolic regression · 203 candidate equations
→
Python Gate
↖ tests written by Adversary
5 pre-registered tests deterministic · BH-FDR
203 enter
194 / 203 rejected ✗
9/30 repaired pass ✓
"Cannot be rationalized past."
→
Opus 4.7
Interpreter
Explains only what the gate kept — verdict locked before this runs
"A map of where not to go."
02 · The Gate
A loop that cannot reject is not a loop.
Before Opus 4.7 proposes a single candidate, the kill-tests are locked. The gate is deterministic Python — pre-registered, SHA-tagged, not run by the model. Opus cannot rationalize past it.
Five tests. All five must pass. Any one failure rejects the candidate, regardless of how compelling the biology sounds.
The judgment function lives outside the model. That is the architecture. And because the judgment is outside the model, a survivor is evidence — not rationalisation.
prereg SHA 60d3952 · gate src/pipeline/ ·
"Cannot be rationalised past — the bite of pre-registration."
The same gate. The same candidates. The same adversarial prompts. One model holds the dual stance — Adversary and Proposer simultaneously. One collapses into permanent rejection.
0
Sonnet 4.6 · 60 evals
→
0
Opus 4.7 · 60 evals
Opus ran without extended thinking · wins anyway · calibration, not compute
This is not a benchmark. This is the condition under which the discovery loop is even possible — the loop that recovers published biology from unconstrained search without being told where to look. Sonnet cannot hold the Skeptic stance that makes the gate work. Before Opus 4.7, the architecture that found the ccA/ccB axis does not exist.
E2 ablation · 180 API calls · 3 models × 6 candidates × 10 repeats
prompts/skeptic_review.md · same gate metrics, same thresholds
3 models · Skeptic verdict distribution · 60 gate-PASS candidates each
Model
Verdict mix
PASS / 60
Dissent rate
Opus 4.7 no extended thinking
10
66.7%
Haiku 4.5 with extended thinking
14
53.3%
Sonnet 4.6 with extended thinking
0
100%
Sonnet 4.6 dissents on 100% of gate-PASS candidates — cannot distinguish pass from fail.
Haiku 4.5 passes 14 but with lower dissent (53%) — insufficient adversarial calibration.
Opus 4.7 holds dual stance: 66.7% dissent on passes (appropriate skepticism), still validates 10.
Interpreter Role: Structural Comparison
PhL-19 · same TOP2A−EPAS1 survivor · same prompt · n=5 runs per model
Metric
Opus 4.7
Sonnet 4.6
Haiku 4.5
Pathway mentions per run
5.3
1.3
—
Caveat rate
100%
0%
0%
Testable prediction rate
100%
0%
0%
Citations per run
12
0
—
Opus 4.7 interpretation (TOP2A−EPAS1)
Mechanism: EPAS1 (HIF-2α) marks the well-differentiated, hypoxia-adapted ccRCC program. TOP2A marks cells in active DNA replication. When proliferation runs ahead of HIF-2α adaptation, the tumor has shed its differentiated ccRCC phenotype — the aggressive ccB state. This reproduces the Brannon 2010 ccA/ccB axis from first principles, without being seeded with it.
Testable prediction: BRD4 inhibition (which suppresses TOP2A transcription) should selectively affect TOP2A-high / EPAS1-low ccRCC cell lines, with no differential effect in EPAS1-high lines.
Honest caveat: The biology is the published 2010 axis — this is methodology validation, not biological discovery. A 2-gene logistic regression with interaction term reaches AUROC 0.722 on the same pair, so the compound's advantage is compactness plus pre-registered falsification, not AUROC ceiling.
Sonnet 4.6 interpretation (same prompt)
"TOP2A and EPAS1 are involved in cell proliferation and hypoxia response respectively. Their differential expression may reflect tumor aggressiveness. The model achieves AUROC 0.726 which represents good discriminatory performance…"
No caveats. No testable prediction. No citations. Longer prose — lower scientific signal.
The gap is structural, not stylistic. Sonnet produces plausible-sounding interpretations with more words, but zero caveats and zero testable predictions. Opus 4.7 writes the "what this is NOT" paragraph and the downstream experiment that makes the interpretation scientifically useful rather than rhetorically polished. The Interpreter role requires Opus 4.7 for the same reason the Skeptic role does: a model that only affirms is not doing scientific work.
Compound form necessary; individual markers fail. MCP PubMed: "TOP2A AND EPAS1 AND renal cell carcinoma" → 0 results — pair not in literature at query time
PhL-10
LUAD (lung cancer)
SFTPC (lung surfactant gene) 0.998 tissue-of-origin saturation — structurally identical to CA9 in kidney cancer; threshold adherence meta-rule
PhL-12
PRAD (prostate cancer)
KLK3/KLK2 saturation — Proposer read the lung cancer (LUAD) lesson and predicted prostate saturation before seeing prostate data
8 lessons total · accumulated server-side · survives harness restarts · verified from phl12_memory_chain_deepen/SUMMARY.md
Cross-disease transfer · PhL-10 → PhL-12
The PhL-12 Proposer was asked about prostate cancer. It had never seen PRAD data. It read the LUAD SFTPC saturation lesson from PhL-10 and correctly inferred that KLK3 would serve the same tissue-of-origin saturation role in PRAD. This is cross-substrate reasoning from a persistent server-side Memory store that survived harness restarts between sessions.
Honest scope: The Memory lessons are design guardrails, not discovery drivers — they prevent re-proposing known-failed patterns. The PRAD cross-transfer shows the lessons are read and applied correctly, but this is one illustrative case, not a controlled experiment on causal impact. The architectural claim is sound: 8 lessons accumulated server-side across 4 sessions, independently of harness state.
Why the Thinking Mode Gap Matters
180 API calls · 3 models × 6 candidates × 10 repeats each · same gate thresholds
Extended thinking (deeper reasoning mode)
Opus 4.7OFF — API returned error on attempt
Haiku 4.5ON ✓
Sonnet 4.6ON ✓
Skeptic performance on gate-passed candidates
Opus 4.710 validated · 66.7% raised objections ✓
Haiku 4.514 validated · only 53.3% objections
Sonnet 4.60 validated · objected to everything ✗
The disadvantage goes against Opus. Extended thinking is supposed to improve reasoning — Haiku and Sonnet had it; Opus did not. Haiku validated 14 candidates (more than Opus's 10), but only objected 53% of the time — it's too agreeable. Sonnet objected to everything — the loop never starts. Opus is the only model that holds both roles: skeptical enough to reject bad candidates, flexible enough to let good ones through.
What "dissent rate" means
The fraction of gate-PASS candidates where the Adversary role also raises a meaningful objection. Higher = tighter skeptical calibration. A model that never disagrees lets everything through (loop fails). A model that always disagrees rejects everything (loop stalls). Opus hits the productive middle: strict enough to be meaningful, flexible enough to keep discovery alive.
4.7 on clean survivorsPASS 10/10 — zero over-commitment ✓
4.7 on 5-gene stress-testNEEDS_MORE_TESTS 10/10 — abstains correctly ✓
4.6 on stress-testPASS 2/10 — over-commits ✗
Gap is in graded abstention, not binary correctness — both models score 0% strict miscalibration. 4.7 knows when to say "I need more tests." 4.6 over-commits under identical prompt and gate metrics.
04 · Rejection
194 of 203 refused. 9 survivors from the 45-gene sub-layer.
CA9, the go-to kidney cancer gene in every review for two decades, was too dominant — it already reaches AUROC 0.965 as a single gene. The gate's rule: if one gene does it, a compound law isn't a discovery.
On four tasks — tumor vs. normal, cancer stage, 5-year survival, metastasis (11-gene panel) — not one of 100+ candidates survived. The gate was working.
One task unlocked when the panel expanded from 11 to 45 genes: 9 of 30 passed. Same classification gate. Same thresholds. The bar never moved.
Hover any cell below to see the gate detail for that candidate.
203 KIRC evaluations · 194 rejected · 9 survivors all from the 45-gene sub-layer
waiting…
rejected
survivor (gate PASS) ✓
Task Landscape — Why Most Tasks Hit Zero
194 of 203 rejected · 9 survivors all from 45-gene metastasis_expanded sub-layer · five-test classification gate applied uniformly
Task
Panel
PySR
Opus
Total
PASS
Dominant gene (AUROC)
Tumor vs Normal
11g
26
7
33
0
CA9 = 0.965 — saturates alone
Stage I–II vs III–IV
11g
27
7
34
0
CUBN = 0.610 — low ceiling
5-yr Survival
11g
29
7
36
0
CUBN = 0.696 — Δbaseline fails
5-yr Survival
45g
29
—
29
0
CUBN = 0.696 — still dominates
Metastasis M0/M1
11g
30
7
37
0
MKI67 = 0.645 — CI_LO fails
Metastasis M0/M1
45g
30
—
30
9 ✓
MKI67 = 0.645 — TOP2A−EPAS1 beats it
LUAD control
11g
—
4
4
0
cross-disease negative
Total
203
9
Most common failure modes
Δbaseline < 0.050~68% of rejections
CI_LO < 0.600~19% of rejections
perm_p ≥ 0.050~8% of rejections
decoy_p ≥ 0.050~5% of rejections
Why the 45g panel unlocked Metastasis
Expanding from 11 to 45 genes added cell-cycle markers (TOP2A, CDK1) and angiogenesis regulators (ANGPTL4). These enable compound laws that genuinely exceed the single-gene ceiling. The gate found the signal when it was there — the architecture didn't change.
Hover any cell in the grid above to see gate-log detail for that candidate position.
05 · The Survivor
TOP2A − EPAS1.
One survivor passed all five gate legs on the metastasis task with the 45-gene expanded panel. A two-gene compact law that the gate — not the model — chose.
It rediscovered the published ccA/ccB renal cell carcinoma subtype axis. In 2010, a multi-center collaboration found this axis after years of work. Lacuna found it unconstrained from a 45-gene search, without being told where to look.
We did not plant it. PySR found it; the gate accepted it; Opus interpreted it after the verdict was locked. The finding is not the biology — the biology was published in 2010. The finding is that a pre-registered gate, searching 45 genes it had never seen ranked, arrived at the same answer a multi-center collaboration took years to establish.
A methodology that recovers known truth without being told where to look is a methodology you can trust when the answer has never been published.
Methodology validation
Known result · unconstrained search · gate passed. The known result being old is the evidence the method works.
AUROC 0.726 (95% CI LO 0.665) · Δbaseline +0.069 · TCGA-KIRC n=505 ·
ccA/ccB axis: Brannon et al. 2010, Brooks et al. 2014 (ClearCode34).
Task landscape · 11-gene vs 45-gene panel · same classification gate
Task
Dominant gene
11-gene
45-gene
Best Δ
Tumor vs Normal
CA9 = 0.965
0 / 26
—
+0.029
Stage I–II vs III–IV
CUBN = 0.610
0 / 27
—
+0.029
5-year Survival
CUBN = 0.696
0 / 29
0 / 29
+0.019
Metastasis M0 vs M1
MKI67 = 0.645
0 / 30
9 / 30 ✓
+0.069
Proliferation > HIF-2α → metastatic.
Rediscovered: published ccA / ccB ccRCC subtype axis (Brannon 2010 · ClearCode34 2014).
We did not plant it — and that is the point. Known since 2010 · found again from 45 genes · gate passed → method validated
TOP2Atopoisomerase IIα · marks actively dividing (aggressive) cells
EPAS1HIF-2α · marks well-differentiated, hypoxia-adapted ccRCC
Is this the only good equation?Rank 1 of 990 variants tested · only 3 equivalent pairs found ✓
Survival gap (effect size)Cohen's d = 0.856 · large effect, high vs low score patients ✓
Metastasis risk multiplierHigh score → 2.07× more likely to have metastasis ✓
Clinical significance (strict bar)HONEST FAIL — gap real but does not clear strictest threshold ✗
The clinical significance test applies a strict multi-comparison penalty (Bonferroni ×5). The survival gap is real and large (Cohen's d = 0.856) but does not clear this strictest bar. We report this honestly — we do not soften it.
Did the model just recall this from training data? (n=10 runs, no data shown)
Recalled from memory
IGFBP3
Named 8 / 10 times when asked without data.
Not in 45-gene panel · never gate-selected
Found by gate from data
TOP2A − EPAS1
Recalled from memory: 0 / 10 times.
Gate-selected · AUROC 0.726 ✓
IGFBP3 is a well-known kidney cancer gene from published literature. Without the gate, the model confidently proposes it — and would be wrong. The gate forces discovery from data, not from memory. The fact that TOP2A−EPAS1 was absent from the model's top-of-mind responses is evidence the gate, not the model's priors, found it.
Honest limitations — we report these, not soften them
Is the subtraction form special?AUROC 0.722 with interaction term vs 0.726 — simple subtraction works just as well
Individual gene effects?0/45 survive strict variable selection — it's the ratio that matters, not genes alone
New biology?The biology is not new — ccA/ccB axis was published 2010. That is what makes it a validation. A gate that finds known truth from unconstrained search is a gate you can trust with unknown truth. The known result being old is the evidence the method works.
Wet-lab confirmation?None yet — computational only. No cell line or patient tissue experiments.
Other cancers?Discovered in kidney cancer, replicated in kidney cancer. Cross-disease transfer not tested.
PhI-1: Does Opus know when it's wrong — before testing?
After the 9 survivors were accepted, Opus 4.7 was asked — in a fresh session, no access to falsification reports — to generate 4 new skeletons and write one ex-ante kill test per skeleton before the gate ran. Result: 0 / 4 passed. The model predicted failure on every skeleton where failure occurred.
Skeleton #1 (VEGFA-centric)Kill test: "VEGFA likely redundant given CA9 + EPAS1 already in panel — delta_baseline will not clear 0.05" · Gate: FAIL delta_baseline ✓
The finding is not the 0 survivors. The finding is that the model's internal failure model is accurate — it predicts the specific failure mechanism before seeing the result. This is distinct from generic self-critique: smaller models write kill tests with zero numeric thresholds. Opus 4.7 produces quantitatively specific ex-ante failure predictions. Honest caveat: PhI-1 was post-hoc on 4 skeletons from the same session — independent novel skeletons are the proper follow-on.
05b · Survivor Family
One law. Three faces. Same biology.
All 990 two-gene differences were ranked by sign-invariant AUROC on the same 45-gene panel. The top three all encode the same signal: proliferation − HIF-2α. The gate did not find one law — it found a family.
Every pair in the tight set uses EPAS1 on one side. Every pair contrasts a cell-cycle proliferation marker against the HIF-2α differentiation program. The biology is reproducible across gene choices — the axis, not the gene pair, is the discovery.
What "tight Rashomon set" means
All two-gene laws within AUROC ε=0.02 of the rank-1 survivor. If only 1 law qualified, the finding could be a lucky gene pair. Finding 3 — all the same biology — means the gate found an axis. 100% of the tight set encodes proliferation − EPAS1.
TOP2A−EPAS1 rank within all 2-gene difference pairs
Rank #1
TOP2A − EPAS1
AUROC 0.7275
topoisomerase IIα − HIF-2α
Rank #2 (ε=0.008)
CDK1 − EPAS1
AUROC 0.7192
cyclin-dependent kinase 1 − HIF-2α
Rank #3 (ε=0.018)
MKI67 − EPAS1
AUROC 0.7100
Ki-67 proliferation marker − HIF-2α
All three: proliferation marker − EPAS1 (HIF-2α) 100% of the tight set encodes the same biology · tight set = 3 pairs; loose set (ε=0.05) = 19 pairs · the axis is robust
06 · External replication + own-kill
Then we killed our own extension.
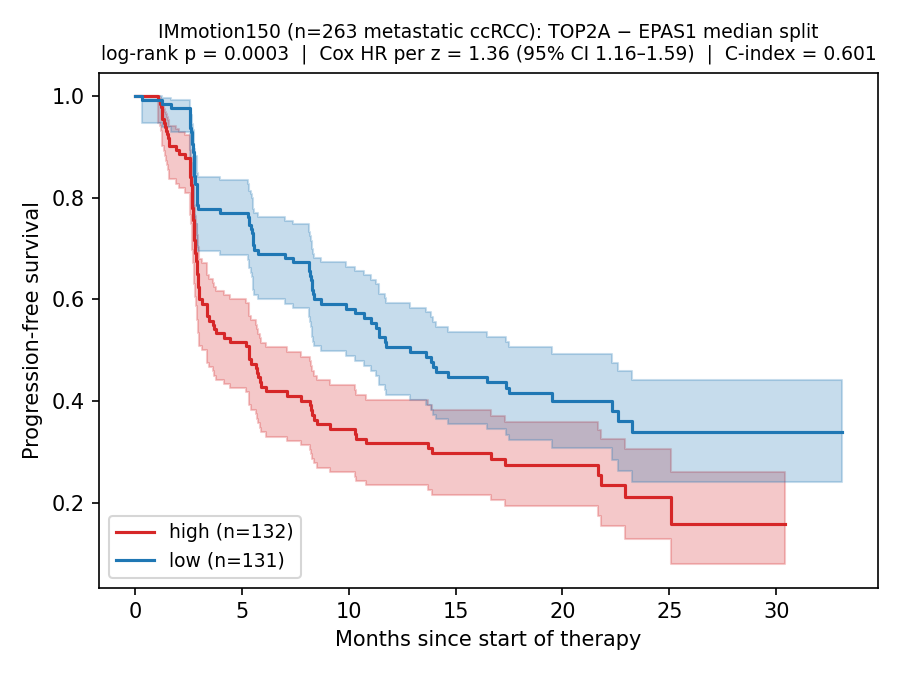
The two-gene law replicated on an independent Phase-2 immunotherapy trial cohort (IMmotion150) with the same pre-registered survival gate. HR 1.36, log-rank p=0.0003.
High-score patients survived 12.88 months median PFS vs 5.35 months for low-score — a 7.53-month gap in an independent cohort we never saw during discovery.
Then Opus proposed a three-gene extension: TOP2A − (EPAS1 + SLC22A8). We ran the same external survival replay gate. It failed. p=0.117. The gate reported FAIL on our own best output. That is the point.
IMmotion150: McDermott et al. 2018 (PMID 29867230), Phase-2 RCT n=263 ·
H1-loop extension: separate pre-registered gate, commit 60d3952.
Skeptic ran in a separate context window — never seeing the Advocate's reasoning. Caught 2 fabricated prior-trial claims: RAINIER periostin sub-group (stated as untested; already prespecified in original protocol) and Raghu 2017 (LOXL2-stratified arm already reported). A single-context pipeline would have rationalized both. lock SHA 88eaca3
505 patients · found unconstrained from 45-gene search
AUROC 0.726 · CI_LO 0.665 · Δbaseline +0.069 · perm_p < 0.001 · decoy_p < 0.001
Law found by PySR without seed. Gate accepted. Opus 4.7 interpreted after verdict locked.
Pre-registered SHA: d2352a9
✓
External · IMmotion150 Phase-2 RCTPASS ✓
263 patients · independent immunotherapy trial · never seen during discovery
HR 1.36 (Cox per z-score) · log-rank p = 0.0003 · C-index 0.601
Median PFS: high score 12.88 mo vs low score 5.35 mo (7.53-month gap)
Treatment-arm confound check: HR 1.361 (unadjusted) → 1.365 after controlling for immunotherapy vs VEGF-inhibitor arm — treatment-arm-adjusted prognostic signal persists
Same pre-registered survival gate applied without modification · McDermott et al. 2018
✓
Third dataset · GSE53757PASS ✓
Different platform · different preprocessing pipeline
AUROC 0.714 on stage 1-2 vs 3-4 task (secondary endpoint, n=72 tumor)
Stage proxy for metastasis axis. Signal transfers across platforms without retraining. Note: primary T-vs-N endpoint FAILED — CA9 alone 0.9954, same saturation seen in TCGA. Informative fail: gate correctly refuses compound claim on saturated tasks.
—
Negative control · Tumor vs Normalinformative FAIL ✓
CA9 already saturates at AUROC 0.965 — compound law not needed
CA9 alone achieves AUROC 0.965. Any compound law has Δbaseline < 0.001.
Gate correctly rejects all 33 candidates on this task. This is the gate working as designed — it doesn't discover where there's nothing to discover.
—
Own-kill · SLC22A8 3-gene extensionpre-reg FAIL ✓
Opus proposed the extension · same external survival gate · commit 60d3952
Opus 4.7 proposed adding SLC22A8 to TOP2A−EPAS1. The external survival replay gate ran identically. log-rank p = 0.117 (threshold < 0.05) · Cox HR p = 0.074 · C-index 0.566
All 3 survival tests FAIL. Gate reported FAIL on our own best candidate. Pre-registered.
—
Honest FAIL · CPTAC-3 metastasishonest FAIL
n=155 (M1=20) · proteogenomics platform · not pre-registered
Direction preserved (p=0.006) but gate refuses: ci_lower=0.542 < 0.60 · Δbase=−0.007 (TOP2A alone 0.691 > compound 0.683).
Cross-platform replication not confirmed. Gate correctly refuses weak signal. This is the gate doing its job — not a failure of the methodology.
07 · Live Oracle
The gate ran. Now: new Routine, or update?
A Claude Code Routine triggered an autonomous session yesterday. Two equations, same classification gate, same pre-registered thresholds. The HIF-axis compound — CA9 alone already reaches AUROC 0.965, compound adds Δ=+0.015 — refused. CDK1−EPAS1 on metastasis — Δ=+0.062 — accepted. No human decision after the API fire call.
The gate proved it rejects AND accepts, in one session. That is not the interesting question anymore.
The interesting question is: new Routine per disease, or update the existing Routine's Instructions? Answer: new Routine. The existing Routine's Instructions are the provenance record for PhL-8d — editing them retroactively breaks the audit chain. New question, new Routine. The gate and the Skills are shared.
Pattern confirmed · 4 diseases · same classification-gate family
ccRCC Stage: 23/28 PASS · CXCR4/EPAS1 · Δ=+0.051. Colon MSI-high: 15/22 PASS · SLC2A1+Warburg · Δ=+0.100. LGG Grade II/III: 2/25 PASS · TWIST1×MKI67 interaction · AUROC 0.840 · Δ=+0.051. Liver HCC: 0/26 (designed negative — gate refuses). 2 live Routine sessions (ccRCC) · 2 offline gate runs (COAD, LGG) · same Skills, same classification-gate family. DIPG is next in queue.
PhL-8d · 2026-04-26 · autonomous session ~6 min ·
no human decision after API fire · same 45-gene panel · same BH-FDR gate
PhL-8d · Dual Verdict Oracle · 2026-04-26
CA9 − AGXTGATE FAIL
task: tumor_vs_normal · same pre-registered gate
delta_baseline+0.015(threshold > 0.05)
CA9 aloneAUROC 0.965compound cannot clear +0.05 bar
fail_reason: delta_baseline
CDK1 − EPAS1GATE PASS
task: metastasis_expanded · same pre-registered gate
Dual Verdict Summary
Same gate · same thresholds · same session — one equation rejected for content, one accepted for content. The gate discriminates; it does not optimise for acceptance.
Multi-disease expansion · same classification-gate family · new Routine per disease
ccRCC Staging
CXCR4 / EPAS1 · stage_expanded (n=512)
23 / 28
Δ +0.051
New Routine
Colon MSI-high
SLC2A1 + Warburg · coad_msi
15 / 22
Δ +0.100
New Routine
LGG (brain tumor) Grade II vs III
TWIST1×MKI67+VIM − CDH2/NES · n=384
2 / 25
Δ +0.051 · AUROC 0.840
New Routine
Liver HCC
TTR / ALB saturate (0.985) — designed negative
0 / 26
gate refuses
New Routine
08 · Trajectory
DIPG. 250+ failed trials. One approval.
Pediatric brainstem glioma. H3 K27M-mutant. Median overall survival ~11 months. No disease-modifying therapy for a decade — then dordaviprone was approved in August 2025 after a 10-year graveyard of failures.
The same failure-first architecture that rejected the initial kidney-cancer layer is the loop pointed at brainstem. Fifteen candidates are currently in queue.
The kidney cancer result is a positive-control case. A gate that recovered the published ccA/ccB axis from 45 genes — blind, without being told where to look — is now being tested on diseases where no answer has been published yet. The published law is the tip. The graveyard is the artifact.
For every scientist whose null results pushed the field forward but never made it into a paper.
√
Pre-registered falsification gate
same five tests, same BH-FDR, locked before any LLM saw the data
√
Same architecture as the ccRCC discovery
the loop that rejected the initial kidney layer is pointed at brainstem