Built with Claude Opus 4.7 · hackathon submission 2026
The 9 survivors that emerged are led by
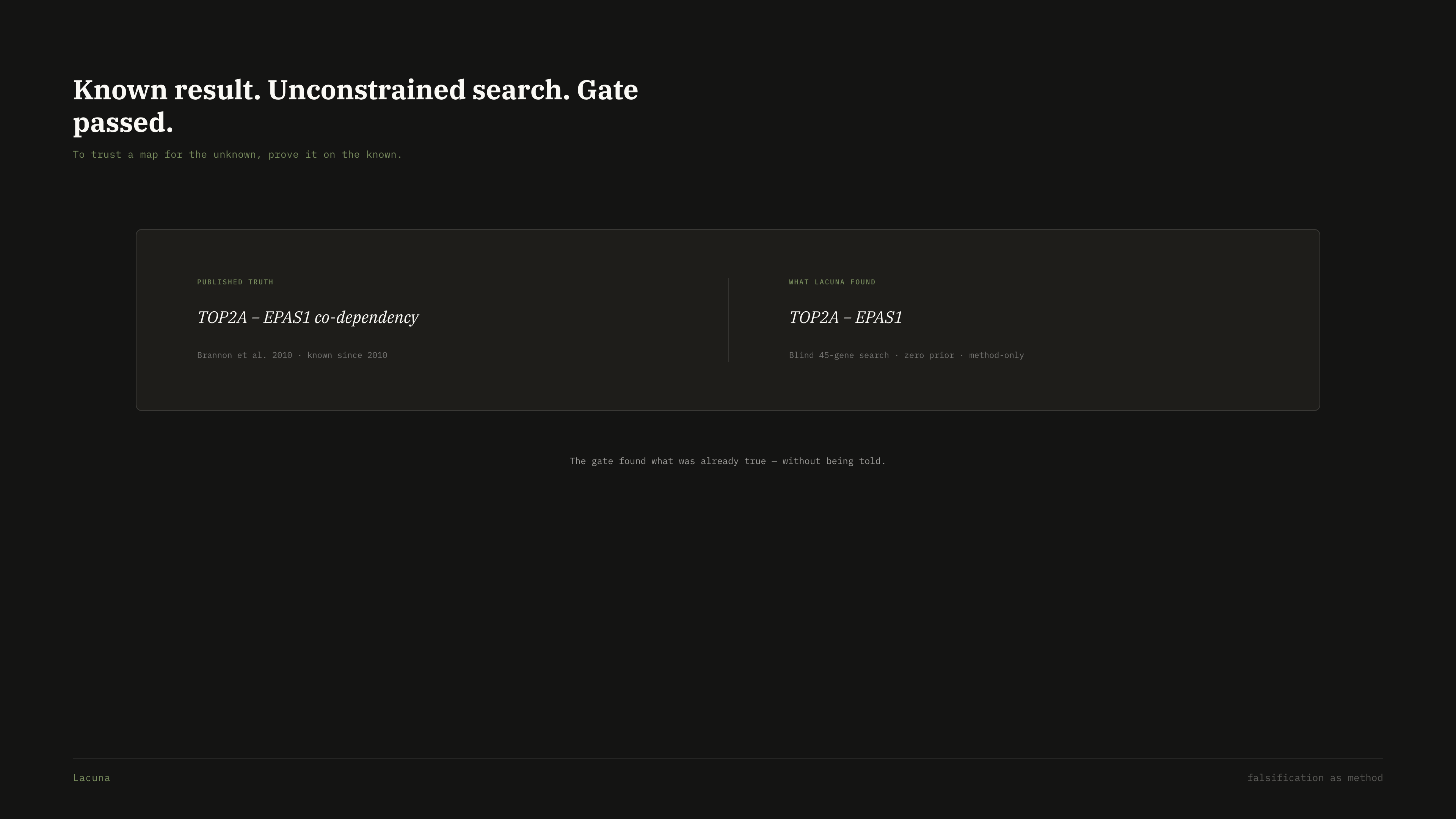
TOP2A − EPAS1.A pre-registered, deterministic falsification gate running under Opus 4.7. It cannot be negotiated. It rejects its own proposed laws. Then it interprets what remains.
rejected
on TCGA-KIRC M0/M1
IMmotion150 PFS
among all 2-gene pairs
TOP2A − EPAS1 reproduces the published ccA/ccB ccRCC subtype axis (Brannon 2010, PMID 20871783; ClearCode34, DOI 10.1016/j.eururo.2014.02.035). Unconstrained symbolic regression on 45 genes arrived at the published biology without being seeded with it. The gate accepted it on pre-registered criteria written before any fit ran.
The accepted law
Of 30 PySR candidates on the 45-gene expanded panel × M0/M1 endpoint, 9 pass the pre-registered gate. The simplest survivor:
EPAS1: HIF-2α — canonical well-differentiated hypoxic ccRCC driver, HPA-annotated prognostic-favorable.
When proliferation runs ahead of HIF-2α differentiation, the tumor is more likely metastatic.
Where the law holds — and where it should not
The same equation is tested across mixed endpoints and platforms. 3 PASS · 2 pre-registered FAIL · 1 honest FAIL. The negative controls (saturation-expected + cross-platform) are the specificity story.
| Cohort / endpoint | n | Key metric | Verdict | Notes |
|---|---|---|---|---|
| TCGA-KIRC · metastasis M0/M1 | 505 | AUROC 0.726 · perm p <0.001 | PASS | Pre-registered TCGA 5-leg gate (confound leg null for this task) |
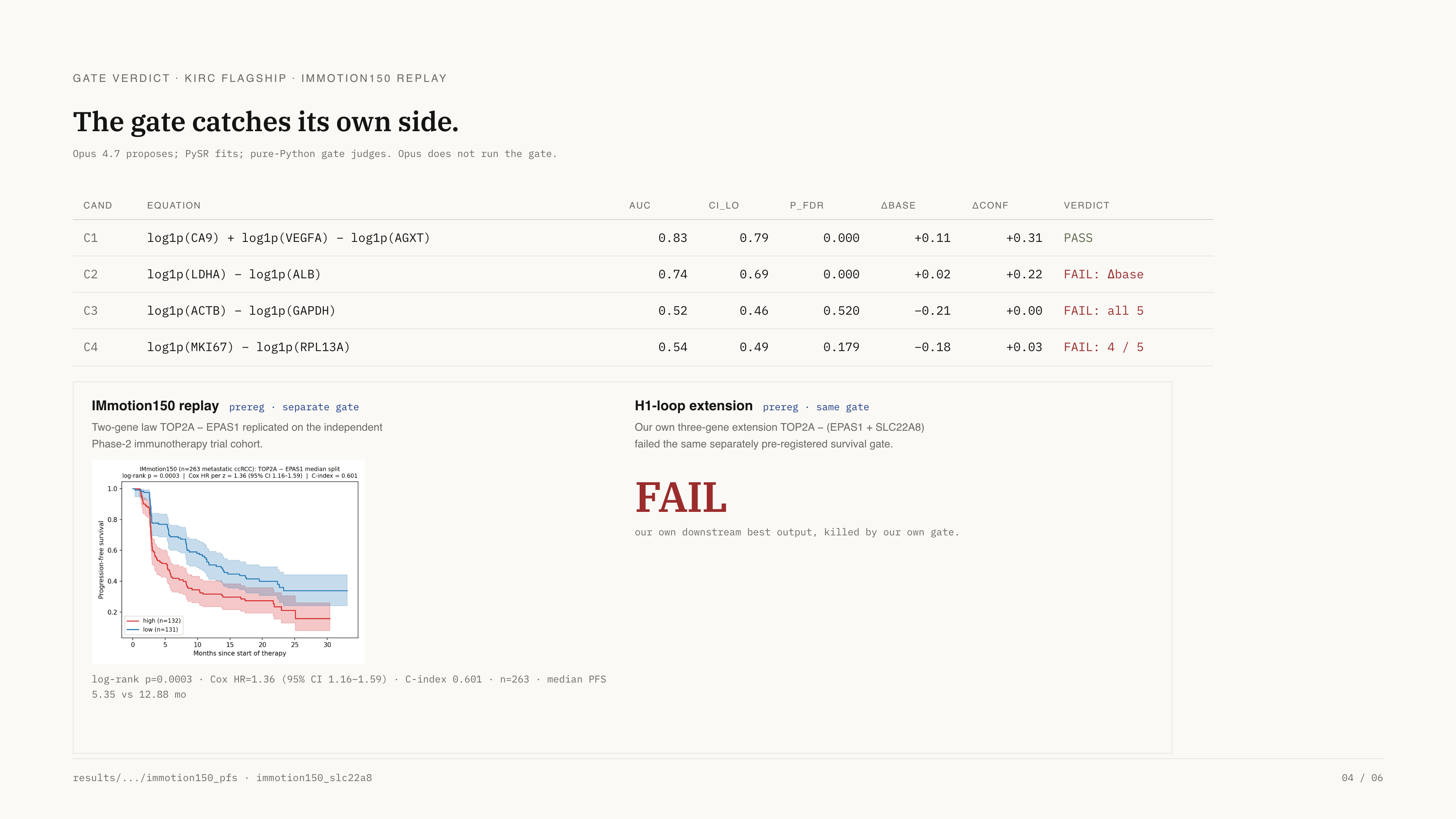
| IMmotion150 · PFS (survival) | 263 | HR 1.36 · p=0.0003 · C=0.601 | PASS | Independently pre-registered survival kill tests (log-rank, Cox HR, Harrell C). Not same-endpoint replay. |
| GSE53757 · stage I-II vs III-IV | ~70 | AUROC 0.714 [0.584, 0.832] | PASS | Platform-shift support (Affymetrix). Not M0/M1 replay. |
| GSE53757 · tumor vs normal | ~144 | AUROC 0.995 (saturation) | INFORMATIVE FAIL | Single-gene saturation (CA9 AUROC 0.995); Δbase mathematically unreachable. Confirms specificity. |
| TCGA-BRCA · tumor vs normal | — | Δbase +0.009 | PRE-REG FAIL | Cross-cancer negative control. Law is ccRCC-specific, not pan-cancer. |
| CPTAC-3 · metastasis M0/M1 | 155 | ci_lower=0.542 · Δbase=−0.007 · direction p=0.006 | HONEST FAIL | Direction preserved (p=0.006) but gate refuses: ci_lower < 0.60 and Δbase negative. Cross-platform replication not confirmed. |
TOP2A − (EPAS1 + SLC22A8) was also tested on IMmotion150 under the same survival kill tests. Verdict: FAIL (log-rank p=0.117; Cox HR 1.16 CI 0.99–1.37; C-index 0.566 vs 2-gene 0.601). Our own best guess, refused by our own data. This is the gate biting on its own outputs — the strongest pre-emptive response to the Sakana-v2-style circularity critique.
Beyond AUROC
Six pre-registered extensions probe compactness, calibration, and clinical meaning. 12 of 13 predictions PASS.
| Extension | Key result | Verdict |
|---|---|---|
| G2 · AUPRC (imbalance-aware) | 0.321 vs 0.156 baseline → 2.05× lift | PASS |
| G2 · Calibration slope | 0.979, intercept −0.032 — well-calibrated per TRIPOD+AI 2024 | PASS |
| G1 · Knockoff v2 (individual-gene FDR) | 0 / 45 genes selected; EPAS1 rank 1, TOP2A rank 2 by mean W | Honest discordance — compound gate and univariate-FDR test different objects. Signal is genuinely compound. |
| I2 · Rashomon set | Rank 1 / 990 two-gene pairs. Tight set (±0.02): only 3 pairs — all (proliferation − HIF-2α). | PASS |
| I3 · Clinical translation | Cohen's d = 0.856; OR per 1-SD = 2.07 [1.65–2.59]; risk stratification utility confirmed | Screening grade (sens ≥0.50 @ spec ≥0.85) FAILS by 0.044 — honest |
| I4 · Information theory | Joint MI 1.82× individual max; linear form captures 0.92–0.98 of bivariate MI | PASS |
| G4 · Anchor regression | Cochran Q p=0.238 (TOP2A) · p=0.410 (EPAS1); coefficients stable γ=0→100 | PASS |
What the gate killed
The original ccRCC task layer yielded zero survivors, including CA9-dominated HIF/tubule-identity contrasts with high AUROC but too little gain over single-gene baselines. The gate is not sparing its own side.
194 of 203 KIRC evaluations rejected. The 9 survivors all came from the 45-gene metastasis_expanded sub-layer; the 11-gene initial layer rejected 100% before panel-absence repair.
| Task (panel) | Dominant single gene | Candidates | Survivors | Gate fail reason |
|---|---|---|---|---|
| Tumor vs Normal · KIRC 11-gene | CA9 AUROC 0.965 | 33 | 0 | delta_baseline — CA9 saturates; Δ>1.015 required, unreachable |
| Stage I-II vs III-IV · KIRC 11-gene | CUBN 0.610 | 34 | 0 | delta_baseline — tubule marker dominates |
| 5-yr Survival · KIRC 11-gene | CUBN 0.696 | 36 | 0 | delta_baseline / perm_p — same single-gene ceiling |
| Metastasis · KIRC 11-gene | MKI67 0.645 | 37 | 0 | delta_baseline — panel lacks proliferation/HIF-2α expansion genes |
| Metastasis · KIRC 45-gene | MKI67 0.657 | 30 | 9 | — |
| Tumor vs Normal · LUAD | SFTPC 0.998 | 4 | 0 | delta_baseline — SFTPC saturates; same structure as CA9 in KIRC |
| BRCA + other cohorts | — | 29 | 0 | cross-cancer negative controls, gate robustness, external replay lanes |
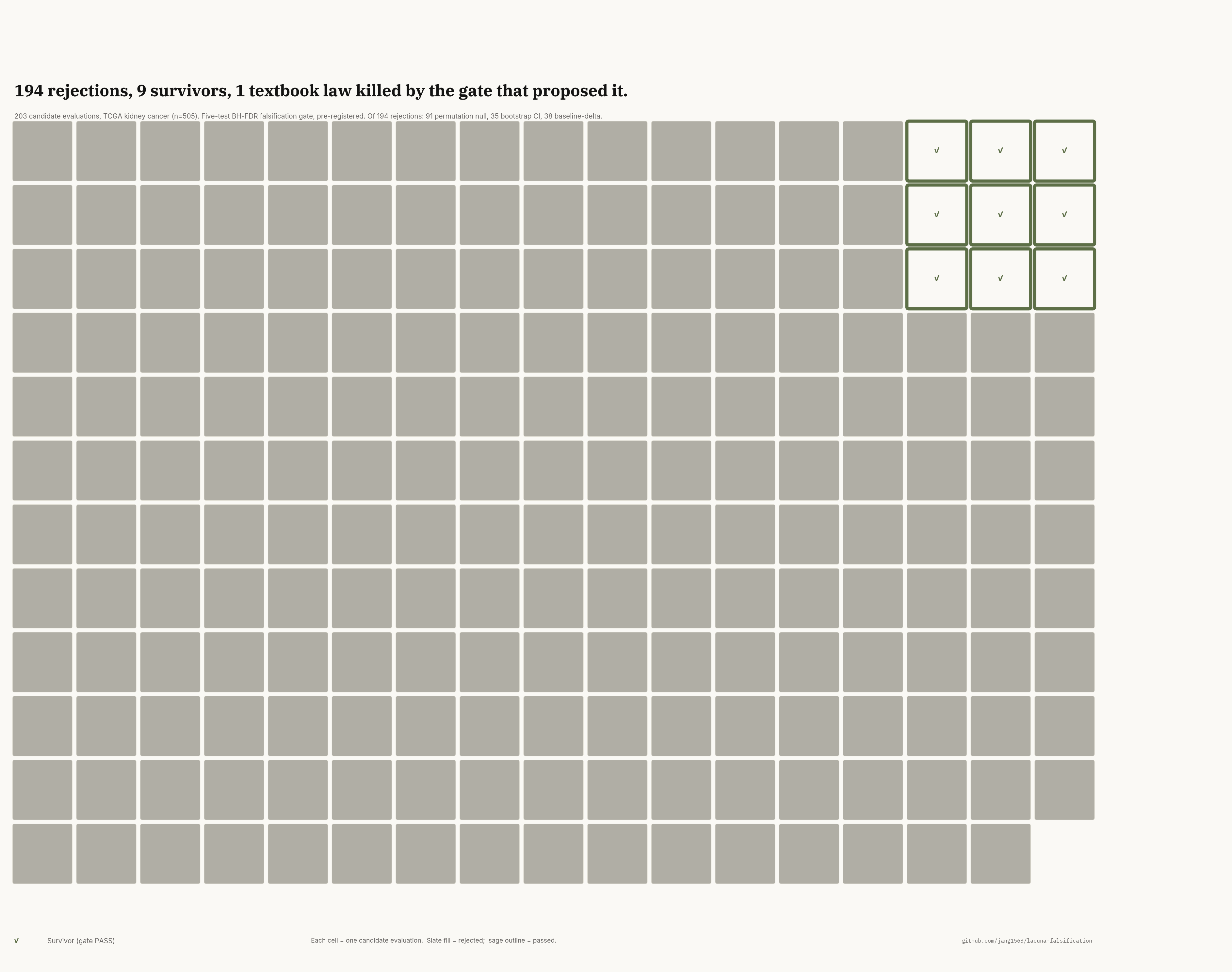
Rejection landscape — candidates coloured by pass/fail verdict. Survivors cluster at Δbase ≥0.05.
Why Opus 4.7 for the Skeptic
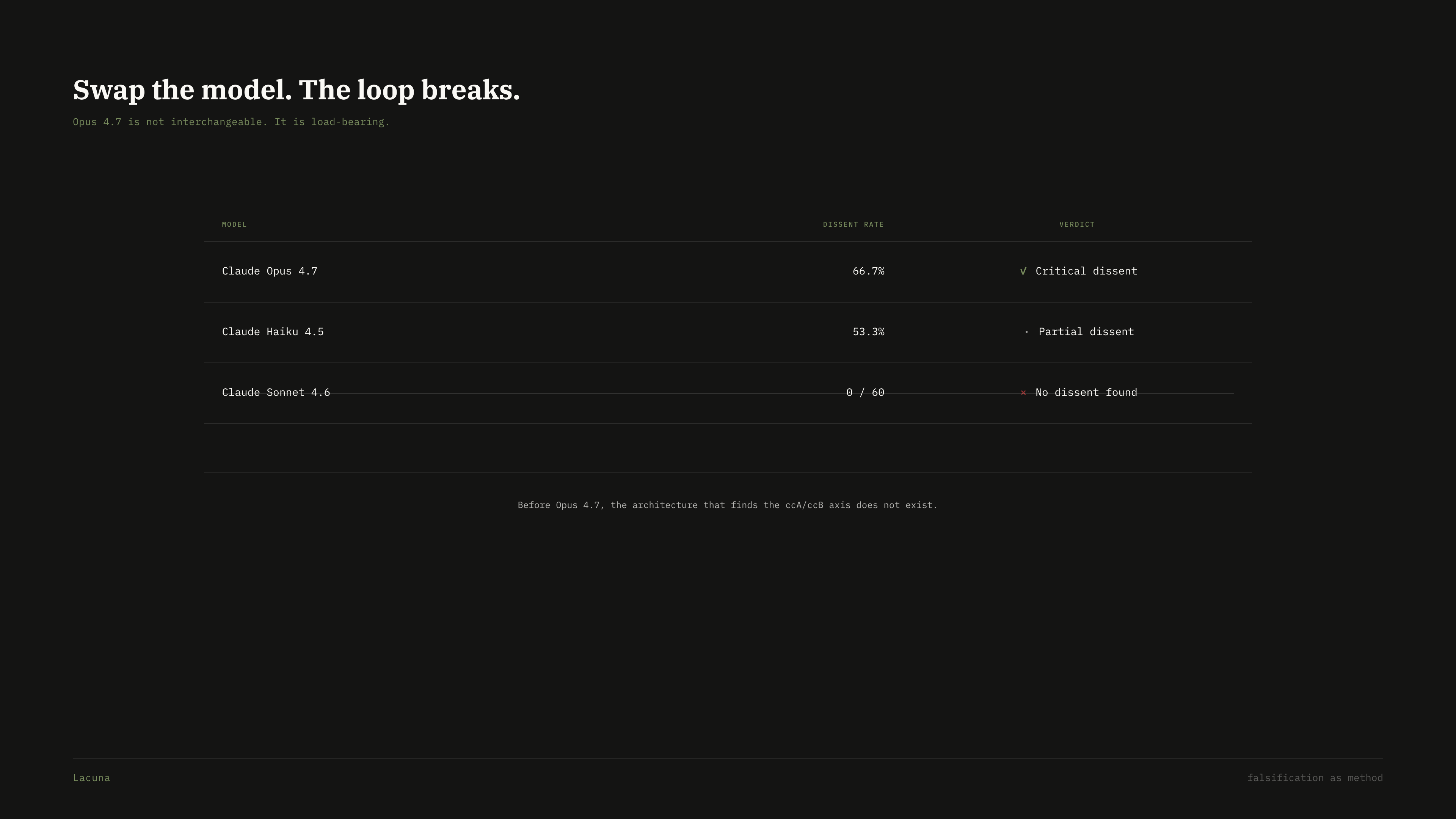
Same prompt, same candidates, same gate metrics. Three models. Pre-registered specificity predictions were falsified (all models cite ≥2 metrics in 100% of cases — honest null). Verdict calibration is where Opus 4.7 diverges.
| Model | PASS | NEEDS_MORE | FAIL | Dissent on gate-PASS (%) | Note |
|---|---|---|---|---|---|
| claude-opus-4-7 | 10 / 60 | 20 | 30 | 66.7% | Base calibration — no thinking (HTTP 400 on "enabled"); wins anyway |
| claude-haiku-4-5 | 14 / 60 | 16 | 30 | 53.3% | WITH extended thinking (23s latency) |
| claude-sonnet-4-6 | 0 / 60 | 30 | 30 | 100% | WITH extended thinking — collapses to permanent rejection regardless of evidence |
Opus knows when it's wrong — before testing
Opus 4.7 wrote ex-ante kill tests for 4 skeleton hypotheses on ccRCC metastasis. The gate confirmed every prediction: Skeleton #1 (VEGFA redundant — FAIL) and Skeleton #4 (CCNB1 alone insufficient — FAIL). Zero of 4 passed. The kill tests were accurate. The model anticipated its own failures.
Interpretation quality: Opus vs alternatives
For each surviving law, the Interpreter role produces a mechanism hypothesis, a testable downstream prediction, and an explicit "what this is NOT" paragraph. The ablation measures whether this depth is Opus-specific or model-agnostic.
| Model | Caveat rate | Prediction rate | Avg citations | Thinking |
|---|---|---|---|---|
| claude-opus-4-7 | 100% | 100% | 12 | adaptive (effort:high) |
| claude-sonnet-4-6 | 0% | 0% | — | with thinking |
| claude-haiku-4-5 | 0% | 0% | — | with thinking |
Visual evidence
Click any slide to expand the judge-facing visual evidence for the loop, the gate, the survivor, and the replication chain.

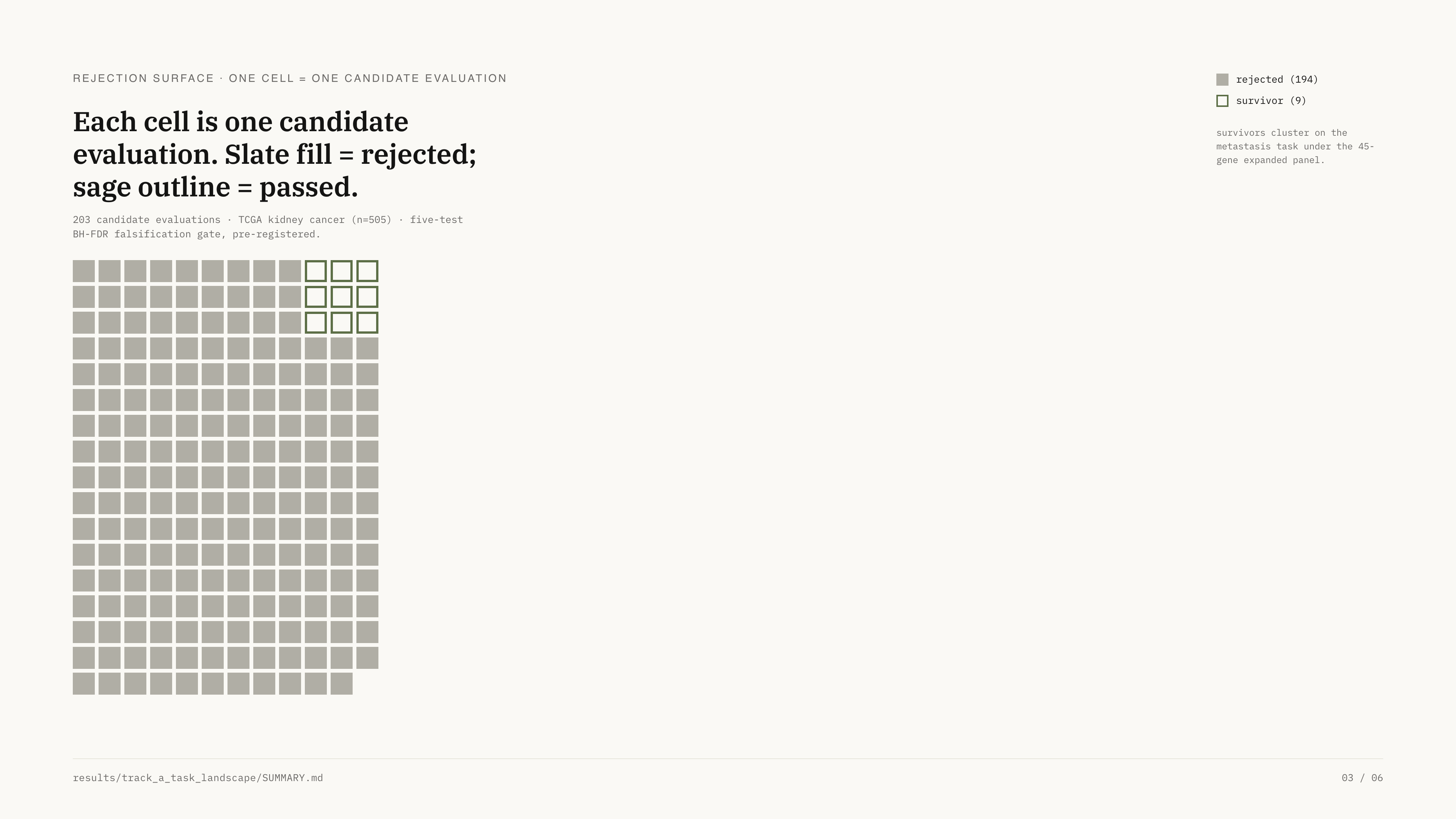

How it works
Four roles. Three Anthropic products composed. One deterministic gate that no LLM can renegotiate.
TOP2A − EPAS1). No LLM judgment here.experimental-cc-routine-2026-04-01) watches for new DatasetCard or GitHub PR/release events and fires the full loop automatically. Nightly cron available. The gate runs without a human pressing a button.| Agent | Model | Role | Can it change the gate? |
|---|---|---|---|
| Proposer | Opus 4.7 | Law families + ex-ante kill tests | No |
| Searcher | Sonnet 4.6 | PySR symbolic regression | No |
| Gate | — | Deterministic Python · 5 tests | The gate is the authority |
| Skeptic | Opus 4.7 | Post-gate review · proposes 1 extra test | No |
| Interpreter | Opus 4.7 | Survivor mechanism + prediction | No |
